为什么引入 我们的业务中经常会遇到穿库的问题,通常可以通过缓存解决。如果数据维度比较多,结果数据集合比较大时,缓存的效果就不明显了。 适合的场景 数据库防止穿库 Google Bigtable,Apache HBase和Apache Cassandra以及Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。 缓存宕机 缓存宕机的场景,使用布隆过滤器会造成一定程度的误判。 WEB拦截器 相同请求拦截防止被***。用户第一次请求,将请求参数放入BloomFilter中,当第二次请求时,先判断请求参数是否被BloomFilter命中。可以提高缓存命中率 恶意地址检测 chrome 浏览器检查是否是恶意地址。首先针对本地BloomFilter检查任何URL,并且仅当BloomFilter返回肯定结果时才对所执行的URL进行全面检查(并且用户警告,如果它也返回肯定结果)。 比特币加速 bitcoin 使用BloomFilter来加速钱包同步。 https://github.com/luw2007/bloomfilter redis本身可以做缓存,为什么不直接返回数据呢? 如果数据量比较大,单个set,会有性能问题? 业务不重要,将全量数据放在redis中,占用服务器大量内存。投入产出不成比例? $ python2default , Oct 6 2017, 22:29:07)for more information.
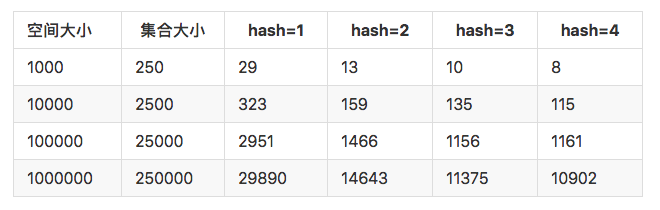
BloomFilter原理 我们常见的将业务字段拼接之后md5,放在一个集合中。md5生成一个固定长度的128bit的串。如果我们用bitmap来表示,则需要 2**128 = 340282366920938463463374607431768211456 bit
算法优点: 算法本身缺点: 元素可以添加到集合中,但不能被删除。 匹配结果只能是“绝对不在集合中”,并不能保证匹配成功的值已经在集合中。 当集合快满时,即接近预估最大容量时,误报的概率会变大。 数据占用空间放大。一般来说,对于1%的误报概率,每个元素少于10比特,与集合中的元素的大小或数量无关。查询过程变慢,hash函数增多,导致每次匹配过程,需要查找多个位(hash个数)来确认是否存在。 如何使用BloomFilter BloomFilter 需要一个大的bitmap来存储。鉴于目前公司现状,最好的存储容器是redis。从github topics: bloom-filter中经过简单的调研。 原生python 调用setbit 构造 BloomFilter lua脚本 Rebloom - Bloom Filter Module for Redis (注:redis Module在redis4.0引入) 使用hiredis 调用redis pyreBloom /bool 进阶:计数过滤器(Counting Filter) 提供了一种在BloomFilter上实现删除操作的方法,而无需重新重新创建过滤器。在计数滤波器中,阵列位置(桶)从单个位扩展为n位计数器。实际上,常规布隆过滤器可以被视为计数过滤器,其桶大小为一位。https://blog.51cto.com/14455981/2476198 www.javathinker.net
[这个贴子最后由 admin 在 2020-03-14 13:27:30 重新编辑]
网站系统异常
系统异常信息
Request URL:
http://www.javathinker.net/WEB-INF/lybbs/jsp/topic.jsp?postID=2760本站管理人员 。















 消息
消息 查看
查看 搜索
搜索 好友
好友 复制
复制 引用
引用